How I Design Systems That See, Read, and Reason
Artificial intelligence is evolving beyond single-task models. Today’s most powerful systems are multimodal — capable of processing images, text, audio, and even sensor data simultaneously. In this post, I’ll walk you through how I design multimodal AI agents, the architecture I use, and the challenges I’ve faced along the way.
🔍 What Is a Multimodal AI Agent?
A multimodal agent is an AI system that can:
- See: interpret visual inputs like photos, diagrams, or video frames.
- Read & Write: understand and generate natural language.
- Reason: combine inputs to make decisions or generate insights.
These agents mimic human cognition more closely than unimodal models. They’re used in applications like autonomous systems, smart assistants, and intelligent search.
🧩 My Architecture Approach
Here’s a simplified view of how I structure a multimodal agent:
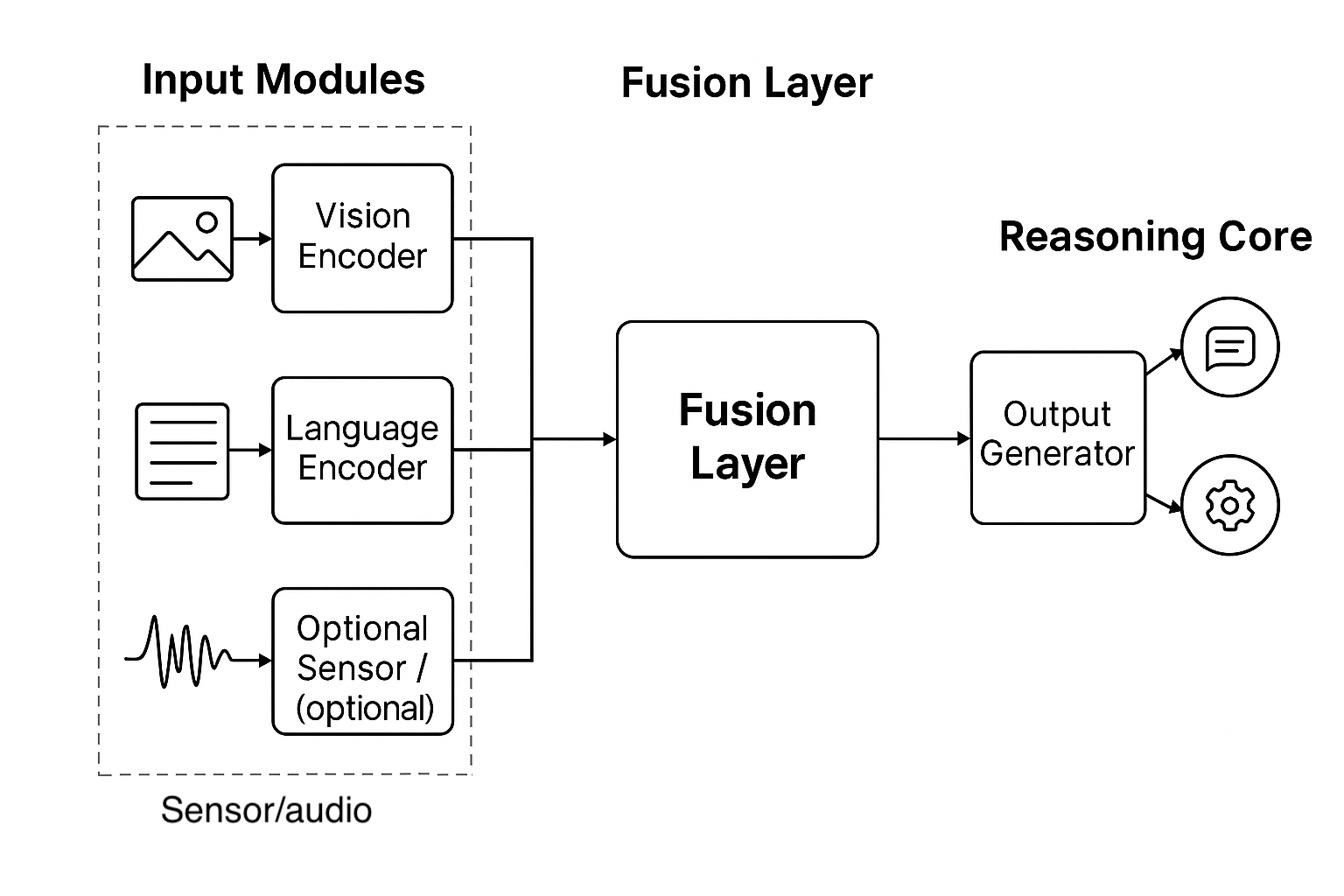
1. Input Modules
- Vision Encoder: CNN or ViT-based model for image features.
- Language Encoder: Transformer-based model (e.g., BERT or custom LLM).
- Optional Sensor/Audio Modules: For edge or embedded use cases.
2. Fusion Layer
- Combines embeddings from each modality.
- Uses attention mechanisms or cross-modal transformers.
3. Reasoning Core
- Decision logic, often built with rule-based systems or reinforcement learning.
- Can include memory modules or context tracking.
4. Output Generator
- Text response, action trigger, or visual output.
- Optimized for latency and interpretability.
⚙️ Tools & Frameworks I Use
- TensorFlow and PyTorch for model development.
- ONNX for cross-platform deployment.
- Docker + Kubernetes for scalable serving.
- Custom pipelines for preprocessing and postprocessing.
🚧 Challenges I’ve Faced
- Latency: Fusion layers can be computationally expensive.
- Data Alignment: Ensuring image and text inputs are contextually matched.
- Interpretability: Making decisions traceable across modalities.
- Deployment: Optimizing for mobile and embedded environments.
🔮 What’s Next
I’m currently experimenting with:
- Multimodal agents for real-time decision support
- Edge deployment using quantized models
- Ethical frameworks for multimodal reasoning
You can follow my progress on GitHub or subscribe for future posts where I’ll share code snippets, demos, and architecture diagrams.
Thanks for reading — let’s keep pushing the boundaries of intelligent systems.
— June